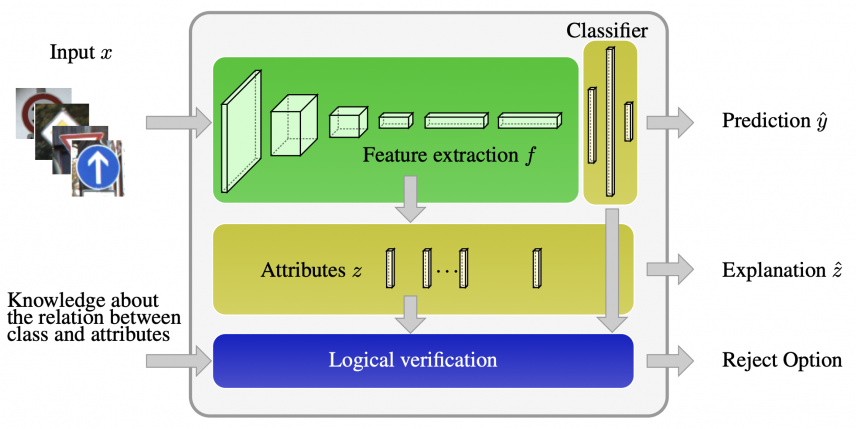
Deploying machine learning models in safety-related domains (e.g. autonomous driving, medical diagnosis) demands for approaches that are explainable, robust against adversarial attacks and aware of the model uncertainty. Recent deep learning models perform extremely well in various inference tasks, but the black-box nature of these approaches leads to a weakness regarding the three requirements mentioned above. Recent advances offer methods to visualize features, describe attribution of the input (e.g. heatmaps), provide textual explanations or reduce dimensionality. However, are explanations for classification tasks dependent or are they independent of each other? For instance, is the shape of an object dependent on the color? What is the effect of using the predicted class for generating explanations and vice versa?
In the context of explainable deep learning models, we present the first analysis of dependencies regarding the probability distribution over the desired image classification outputs and the explaining variables (e.g. attributes, texts, heatmaps). Therefore, we perform an Explanation Dependency Decomposition (EDD). We analyze the implications of the different dependencies and propose two ways of generating the explanation. Finally, we use the explanation to verify (accept or reject) the prediction.
[arXiv], Presented at CVPR Workshops 2019: [Dependable Deep Detectors]